
Software quality has always been a boardroom issue and now it has become existential. Engineering leaders are being asked to move faster than ever, deliver innovation continuously, and cut costs at the same time. GenAI coding assistants promise acceleration, and they do deliver, as developers can now generate hundreds of lines of code in seconds. But speed without quality is a recipe for disaster.
The uncomfortable truth is that With GenAI, Engineering Output Grows Exponentially but so do the Quality Challenges.
Recent studies show that large language models frequently replicate errors they’ve seen in training data. In fact, GPT-4o was found to copy known bugs in 82% of cases, and GPT-3.5 did so over 50% of the time (Bank Info Security). And even when teams turn to GenAI for fixing bugs, the results call for risk management from development teams. McKinsey warns that AI assistants “often provide incorrect coding recommendations and even introduce errors in the code” (McKinsey) . Translation: whether you’re shipping new features or patching old ones, GenAI can accelerate delivery but it can also accelerate the spread of mistakes if left unchecked.
When these tools generate not just the code, but also the tests, the risks could multiply. Instead of catching each other’s mistakes, code and tests can reinforce the same flawed assumptions - creating a vicious cycle of undetected bugs.
For leaders, the question isn’t whether to use AI in development because now it is table stakes. The question is: how do you safeguard quality in the GenAI era?
The Evolution of Quality Metrics and Why They’re Broken
For decades, engineering leaders have wrestled with the same quality paradox: how do you move faster without breaking things? In the waterfall era, quality was measured by defect counts and test completion rates. Agile brought new metrics like velocity and sprint burndown charts, but quality was often reduced to a single line in the definition of done: “tests passing.”
Then came DevOps and CI/CD, which promised to automate away the risk of failure. In reality, the complexity of distributed architectures meant that even well-tested releases frequently broke in production. Now, with GenAI accelerating the pace of code creation, the stakes are higher than ever.
Traditional metrics like code coverage or the number of passing regression tests create the illusion of safety. Boards and executives love them because they’re simple, quantifiable, and easy to report. But as many CIOs have discovered, you can hit 90% coverage and still ship catastrophic bugs.
Today, software quality is a business metric instead of just a software metric. Customer trust, revenue continuity, and innovation velocity all hinge on whether leaders adopt a new, correlated approach to measuring and ensuring quality.
A Vicious Cycle: When Code and Tests Are Both AI-Generated
It’s tempting to think: “If AI can write the code, it can also write the tests.” But this creates one of the most dangerous feedback loops in modern engineering.
Researchers have shown that when given buggy source code, LLMs also generated flawed test cases that failed to catch the errors, reducing test accuracy significantly (Measuring the Influence of Incorrect Code in Test Generation). In other words, AI doesn’t just inherit developer assumptions; it doubles down on them.
Similar blind spots have been documented in When AI-produced code goes bad. If your code and your tests are both AI-generated, you’re not testing reality: you’re testing AI’s imagination.
Every Line of Code Is a Risk - Even Tested Ones
Untested code is an obvious liability. But even tested code carries risk if the tests aren’t comprehensive or regression aware. Regression defects are particularly insidious. They occur when a change in one area of code inadvertently breaks something elsewhere. Regression bugs are so common that they account for 20–50% of all defects in many enterprise systems.
And regression testing is far from foolproof. Teams often run incomplete suites, skip edge cases, or lack visibility into which areas are truly covered. As one QA leader put it, “bugs still slip through regression testing because of missing structure, limited visibility, and ignored failures” (Why Bugs Still Slip Through Regression Testing).
Harness, a DevOps platform provider, admitted in their own engineering blog that regressions were slipping into production because quality processes weren’t keeping up with release velocity (Harness).
These proposed fixes - tighter test case management, improved visibility, and dashboards built on defect leakage - are useful steps forward. But they remain manual, reactive, and metrics driven. They force teams to chase numbers after the fact rather than predict risks in advance. And in a world where GenAI is increasing engineering output by 10x, this model simply won’t scale. You can’t fight exponential code creation with incremental test management.
What’s needed is a new foundation: one that moves beyond surface-level metrics and into correlated intelligence. Because even the most celebrated measures of quality, like code coverage or test coverage, are dangerously easy to game. They look good on paper, but too often they fail to reveal whether your releases are truly safe.
The Metrics Trap: Why Coverage Alone Doesn’t Guarantee Quality
It’s tempting to respond to regression challenges by doubling down on metrics. If we can just hit 80% code coverage, or show that all requirements have passing tests, then surely quality must be improving, right? Unfortunately, this is the trap many engineering leaders fall into.
Coverage numbers are simple, reportable, and easy to put on a dashboard. Boards and executives love them because they look like progress. But coverage by itself is a vanity metric: it measures activity, not effectiveness. You can touch every line of code and still miss the edge cases that trigger real-world failures. You can mark every requirement as tested yet still regress in production because the regression occurred in a functionality that was not even changed.
High code coverage doesn’t mean critical scenarios are tested. High test coverage doesn’t mean code paths are exercised thoroughly. Both metrics are necessary but insufficient.
QUESTION
ISN’T
BUT
From Quality to Engineering Intelligence
Coverage-driven offerings already exist in the market. Many tools can show you which lines of code are exercised by tests or where recent changes intersect with regression suites. These are useful, but they only scratch the surface. They’re still rooted in isolated metrics - snapshots of coverage or test execution at a single point in time.
The need of the hour is to move beyond siloed coverage dashboards and into true engineering intelligence: insights derived from across the entire lifecycle - planning, coding, testing, release, and production. Only by correlating these signals can leaders see not just what was tested, but where risks are building, where developer productivity is being lost, and where the next defect is most likely to emerge.
Every hour spent fixing bugs is an hour not spent on new features.Reactive maintenance is the silent killer of developer productivity.
CleverDev’s vision is to unify these signals into one correlated platform, giving engineering leaders the ability to see not just where they are, but where they’re heading.
CleverDev: Correlated Engineering Intelligence in Action
Most tools today stop at coverage metrics or defect dashboards. They show slices of the truth, but they don’t connect the dots. CleverDev is built to change that.
By correlating signals across planning, coding, testing, release, and production, CleverDev delivers a single intelligence layer that predicts where failures are most likely to occur. Instead of looking backward at defect counts or test pass rates, leaders gain forward-looking visibility into emerging hotspots, innovation bottlenecks, and hidden risks.
With CleverDev, engineering leaders can act before problems surface — protecting velocity, reducing rework, and giving teams the confidence to innovate faster.
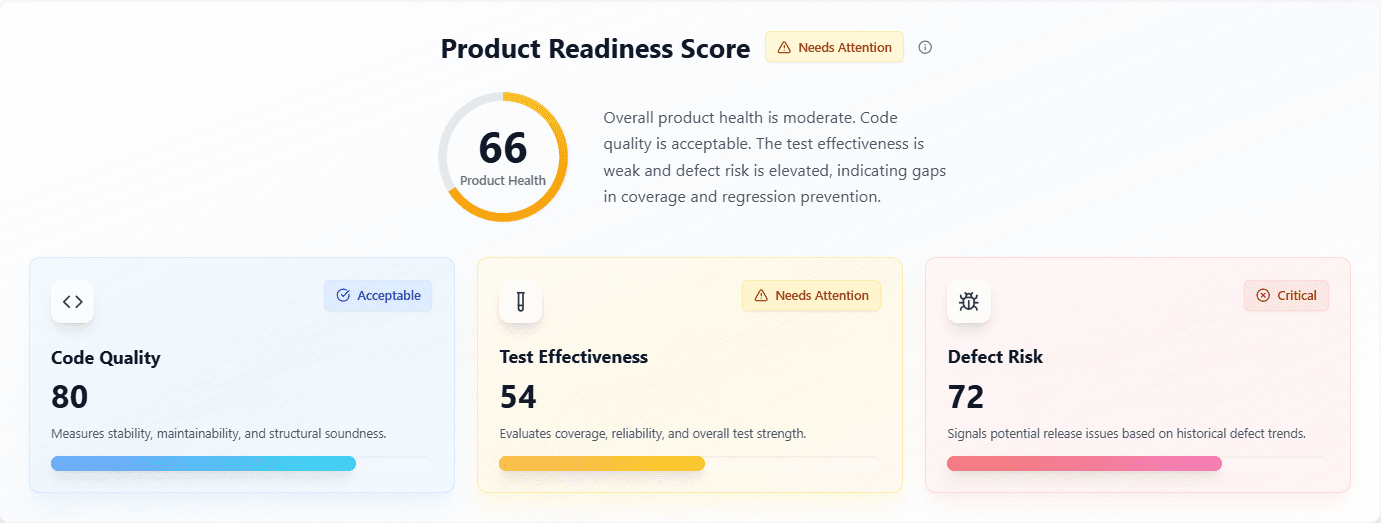
The Leadership Imperative and Call to Action
Engineering leaders are under pressure from every direction: executives want faster releases, customers expect flawless experiences, and developers are already stretched thin. In this environment, success depends on asking the right questions and having the intelligence to answer them.
The strategic questions every engineering leader must answer in the GenAI era:
Answering these questions requires more than dashboards or isolated metrics. It requires correlated engineering intelligence that connects the full lifecycle into one view of risk and productivity.
As a leader, you are safeguarding innovation velocity, customer trust, and your organization’s reputation. GenAI has changed the speed at which software is written, but it hasn’t changed this rule: untested or poorly tested code will still break in production.
The leaders who act now - moving beyond metrics to correlated intelligence - will be the ones who deliver both speed and resilience, protecting today’s velocity while building tomorrow’s advantage.
At CleverDev, that’s exactly what we’re building.